

TL;DR
Spoken queries are longer, contextual, and intent-rich.
Voice-ready social content must be answer-first and structurally clear.
The ASK model helps map natural-language intent to format execution.
Voice optimization improves AI retrieval and user comprehension.
Quick Definition
Voice optimization for social media means designing posts, scripts, captions, and structured blocks so natural spoken questions can be matched and answered quickly. It is less about traditional keyword density and more about intent clarity and answer architecture.
Why Voice Changes Social Content Design

Voice Search Infographic
Typed queries are usually compressed; spoken queries are conversational. That single shift changes content planning.
A user who types might write: “repurpose blog social.” A user who speaks might ask: “How can I turn one blog post into content for multiple platforms without burning out?”
The second query includes constraints, goals, and context. Content that only targets short keywords often misses these richer question patterns.
Counterargument: “Voice is mostly for assistants and web search, not social platforms.”
Trade-off: direct voice traffic may vary by channel, but user behavior has already shifted toward spoken-language phrasing across all surfaces. Social content that mirrors natural language is easier to retrieve, summarize, and reuse.
Edge case: visual-first channels may show weaker direct voice intent, but captions, overlays, and hooks still benefit from conversational query patterns.
Concrete scenario: a creator replaces a generic title (“3 repurposing hacks”) with a spoken-intent line (“How do I repurpose one blog into a week of social posts?”). Saves and shares increase due to clearer utility.
Common misconception: voice optimization means adding a few question marks. It means rethinking structure.
Takeaway: Spoken language raises the standard for content clarity.
Takeaway: Voice readiness is a structural advantage, not a formatting trick.
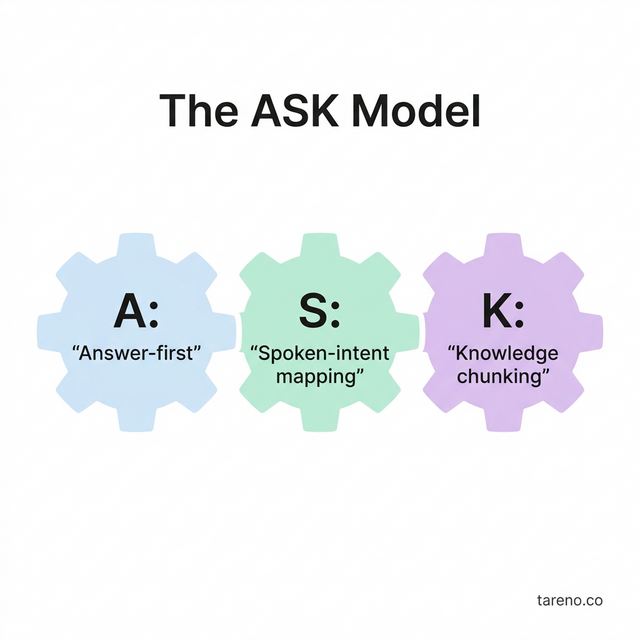
The ASK Model
Use ASK to build voice-ready social content:
A — Answer-first: start with the direct answer in one or two lines.
S — Spoken-intent mapping: align wording with real audience questions.
K — Knowledge chunking: split content into retrievable blocks.
Counterargument: “Answer-first ruins storytelling.”
Trade-off: answer-first can feel blunt if overused, but delayed value harms retention and retrievability. Best practice is answer-first opening plus narrative expansion.
Edge case: personality-led creators can keep their tone by placing answer-first lines in captions or pinned comments while maintaining story flow in video.
Concrete scenario: a brand starts each post with “Short answer:” then adds framework, trade-offs, and implementation steps. Engagement quality improves because users understand relevance immediately.
Common misconception: voice-ready means simplified. Good voice-ready content is clear first, deep second.
Takeaway: ASK balances accessibility and authority.
Takeaway: Clarity at the top increases downstream depth consumption.
The ASK Model for Voice Optimization
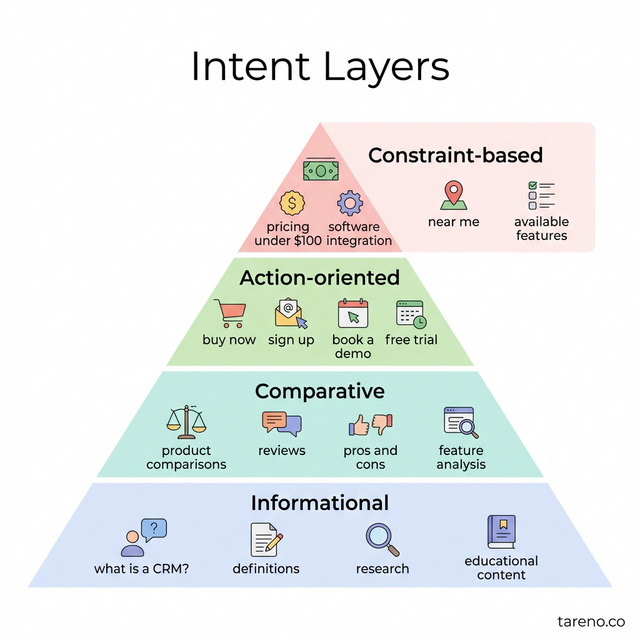
Intent Layers for Spoken Queries
Informational
“What is…?”, “How does…?”, “Why does…?”
Comparative
“X vs Y?”, “Which is better for…?”
Action-oriented
“What should I do first?”, “How do I start?”
Constraint-based
“…with low budget?”, “…as a solo creator?”, “…in 30 days?”
Counterargument: “Intent segmentation is too academic for social.”
Trade-off: if used mechanically, yes. But intent segmentation helps teams stop publishing vague generalities and start creating answerable content.
Edge case: trend content often blends intents. Pick one primary intent and one secondary intent to keep structure coherent.
Concrete scenario: a team rewrites content around action-intent questions and sees stronger retention and saves without increasing post frequency.
Common misconception: reach alone defines success. For voice-ready strategy, relevance and answer quality matter more.
Takeaway: Intent-first design increases practical usefulness.
Takeaway: Better intent matching improves both user and AI interpretation.
Voice Search Intent Layers Pyramid
Architecture for Voice-Ready Social Assets
A robust voice-ready asset should include:
quick definition
named framework
when-to-use / when-not-to-use boundary
comparison element (table/checklist)
FAQ in natural language
Counterargument: “This is too templated.”
Trade-off: over-templating can reduce originality, but no structure reduces extraction quality. Use a stable skeleton with flexible examples.
Edge case: short videos can implement compact architecture: direct hook, one framework point, one practical step, and pinned FAQ.
Concrete scenario: educational carousel adds concise FAQ card at end. Completion rate and shares increase because users can quickly map value.
Common misconception: structure kills creativity. Structure protects signal.
Takeaway: Architecture improves repeatability and retrieval.
Takeaway: Creativity performs better on top of clear scaffolding.
Tool Evaluation Rule (3 Categories × 3 Criteria)
Category 1: Transcript/Extraction
transcript accuracy
context retention
export flexibility
Category 2: Structuring
answer-first template support
framework/checklist block control
FAQ assembly speed
Category 3: Distribution/Review
multi-channel scheduling reliability
caption/pinned-comment workflow support
intent-level performance visibility
Takeaway: Tools should enforce consistency in voice-ready structure.
30-Day Implementation Plan
Week 1: Audit
identify high-performing spoken-style queries
classify existing content by intent
Week 2: Template rollout
deploy ASK-based templates
standardize answer-first openings
Week 3: Repurpose
convert existing assets into spoken-intent variants
align captions with verbal query phrasing
Week 4: Evaluate
review saves, watch-time quality, and qualified engagement
retire low-clarity formats
Counterargument: “30 days is too short.”
Trade-off: deep outcomes need more time, but 30 days is enough to validate process quality and intent fit.
Edge case: low-volume niches may need longer for statistically clear results.
Concrete scenario: brand rewrites ten posts into voice-ready format and improves qualified interaction despite similar reach.
Common misconception: optimization equals reach chasing. In voice contexts, answer quality compounds.
Takeaway: Early gains appear in relevance, not always impressions.
Takeaway: Process quality drives durable performance.
Common Failure Patterns
keyword stuffing without direct answers
long intros before value delivery
no decision boundaries
disconnected captions and scripts
missing FAQ support
Counterargument: “Users don’t read long captions.”
Trade-off: not everyone reads, but structured captions improve retrieval and comprehension.
Edge case: if attention is short, move detail into pinned comments and linked long-form content.
Concrete scenario: replacing vague hooks with direct answer lines improves completion and save rates.
Common misconception: voice optimization is separate from content strategy. It is core strategy.
Takeaway: Voice-ready content is clearer, not merely “optimized.”
Takeaway: Retrieval quality starts with answer architecture.
FAQ
Does voice optimization really matter for social media?
Yes, because user phrasing patterns increasingly mirror spoken natural language.
Should every post be optimized for voice?
No. Prioritize educational and authority content first.
Is keyword research still relevant?
Yes, but keyword signals should be translated into natural-language intent structures.
Can short videos be voice-optimized?
Yes—use answer-first hooks, aligned captions, and FAQ support.
What is the first step for teams?
Audit existing content and deploy one standardized ASK template.
What metric should be prioritized?
Qualified engagement quality and content comprehension signals.
Conclusion
Voice behavior is changing how users discover and evaluate content. Brands that optimize social assets for spoken intent—through answer-first structure, intent mapping, and reusable framework blocks—gain a durable relevance advantage.
Key Takeaways
Spoken queries demand answer-first clarity.
ASK model creates repeatable voice-ready structure.
Intent mapping improves usefulness and retrieval.
Structured templates protect quality at scale.
Audio Version
Audio Version



