

TL;DR
Most teams underperform because they scale activity before they scale decision quality.
The SIGNAL Loop helps you operationalize contest-led growth systems with clear thresholds, owners, and review cycles.
The right tooling only works when mapped to a specific bottleneck and a measurable outcome.
A practical rollout starts narrow, adds guardrails early, and expands only after stable quality.
Failure modes are predictable: unclear escalation, weak definitions, and over-automation without exception design.
Quick definition
Social Media Contest Strategy is not a list of tricks. It is the set of rules, workflows, and governance decisions that let a team execute reliably when demand increases. In practice, that means defining what gets standardized, what remains human-led, and how exceptions move through the system. Teams that treat this as a capability—rather than a campaign tactic—usually improve both efficiency and quality over time.
For Social media managers, agency operators, and growth teams, the central question is not “Can we do more?” but “Can we do more without quality collapse?” A robust operating model answers that question with thresholds, ownership, and routine audits. Without those layers, short-term gains often hide growing risk: inconsistent outputs, delayed responses, internal overload, and eventual churn.
The SIGNAL Loop framework
I use the SIGNAL Loop because it forces teams to balance speed with control.
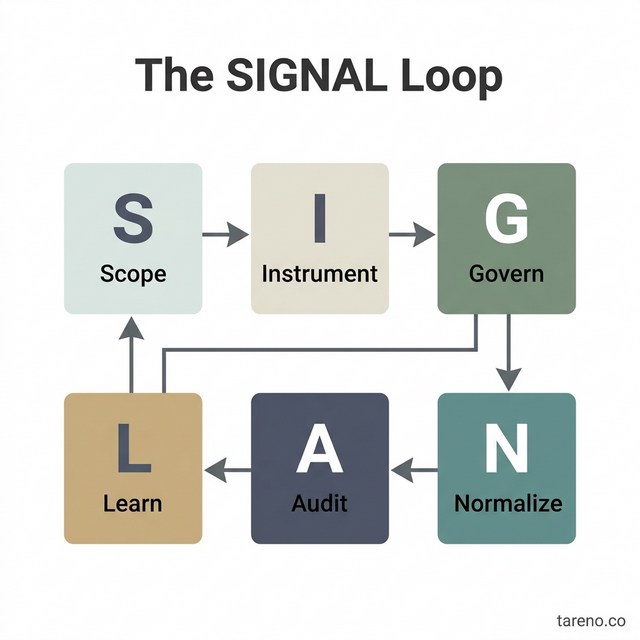
The SIGNAL Loop Framework Visualization
S — Scope the use case
Start by narrowing the use case to one visible bottleneck. Many teams try to redesign the full social stack at once and lose clarity. Scope should include: audience segment, channel, content type, response class, and success window. If those five are not explicit, your system will drift.
Mini-example: a team running a campaign notices that qualified responses are buried under repetitive interactions. Instead of changing every workflow, they scope one process: first-touch handling for campaign comments and DMs during a two-week launch.
I — Instrument core metrics and thresholds
Metrics are only useful when attached to decision thresholds. Track no more than five core metrics initially: throughput, cycle time, error/rework rate, escalation volume, and conversion quality. Then define action triggers. For instance, if rework exceeds 8% for two weeks, pause expansion and fix the handoff layer.
This step prevents vanity reporting. A dashboard that looks “active” can still hide poor decision quality. Instrumentation should answer operational questions: where is flow blocked, where quality drops, and where team stress rises.
G — Govern rules and ownership
Governance is the difference between experimentation and chaos. Define one owner per workflow, one reviewer per exception class, and one escalation path per risk category. Keep this simple enough that new team members can understand it in one page.
A common failure is shared ownership with unclear authority. In busy weeks, that structure creates delayed decisions and inconsistent outcomes. Governance should be explicit about who can approve templates, who can pause automation, and who signs off on policy-sensitive replies.
N — Normalize execution
Normalization means converting best effort into repeatable process. Create templates, routing logic, QA checklists, and handoff tags. The goal is not rigid scripting; it is reducing random variation in routine cases so humans can focus on non-routine ones.
This is where Comments Manager can fit operationally. Use it to reduce repetitive load in a defined part of the workflow, then measure whether cycle time and rework improve. If metrics do not improve, rollback quickly and adjust scope.
A — Audit outcomes
Weekly audits should review three layers: output quality, system behavior, and team load. Output quality asks, “Did we deliver the right outcome?” System behavior asks, “Did our rules route correctly?” Team load asks, “Is this model sustainable?”
Audit meetings fail when they become narrative-only. Use a fixed checklist and require one corrective action per failed threshold.
L — Learn with bounded experiments
Learning is not random optimization. Run bounded experiments with one variable changed at a time and a clear stop condition. Example: test a tighter escalation threshold for two weeks. Keep all other settings stable, then compare results.
The most scalable teams treat every iteration as a documented decision, not a memory in someone’s head.
When to use this model — and when not to
Use this model when you see one or more of the following:
Rising volume with unstable quality.
Team members overloaded by repetitive work.
Slow response cycles that hurt conversion windows.
Frequent confusion about ownership or escalation.
Do not use this model as a substitute for missing strategy. If your positioning, audience intent, or offer quality is unclear, better operations will not solve the core issue. Also avoid full automation in areas requiring nuanced judgment (sensitive support cases, legal-adjacent claims, crisis communication).
Mini-example: one brand attempted complete automation during a product issue week. The system stayed “on plan,” but sentiment worsened because exceptions were routed too late. The fix was not more templates; it was earlier human intervention criteria.
Comparison: three operating models
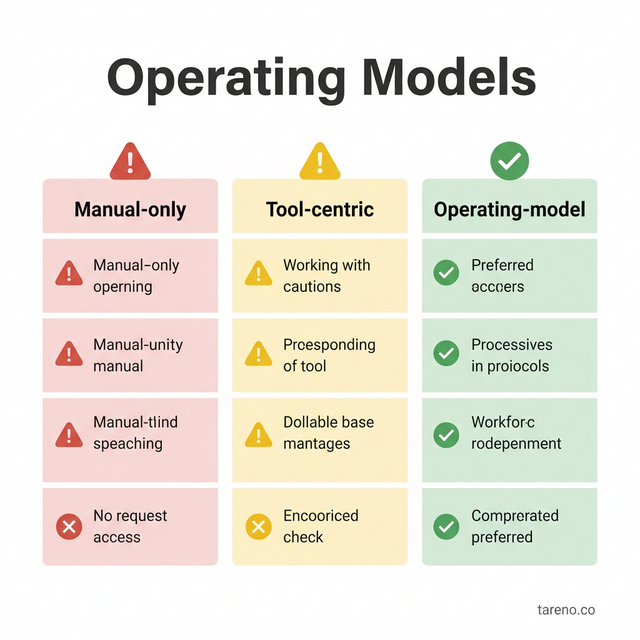
Comparison of Social Operating Models
1) Manual-only model
Strengths: high contextual nuance, low setup effort.
Weaknesses: poor scalability, inconsistent execution across team members, heavy burnout risk.
Best for: early-stage teams with low volume and expert operators.
2) Tool-centric automation model
Strengths: speed gains in routine tasks, visible throughput improvement.
Weaknesses: can create brittle workflows if governance is weak.
Best for: teams with stable playbooks but limited process discipline.
3) Operating-model-centric system (recommended)
Strengths: durable quality under scale, clearer accountability, better long-term learning.
Weaknesses: requires upfront design work and cross-role alignment.
Best for: teams planning sustained growth across channels.
Decision rule: if your weekly exception volume is growing faster than your throughput, move from tool-centric to operating-model-centric design immediately.
Step-by-step implementation playbook
Step 1: Baseline your current workflow
Map the real path from signal to outcome: intake, classification, action, review, and closure. Most teams discover hidden loops, duplicate handling, or silent delays.
Step 2: Select one high-friction use case
Choose one workflow where delay or inconsistency is expensive. Set a 30-day target and one owner.
Step 3: Define quality boundaries
Write what “good” looks like in observable terms: tone accuracy, policy alignment, turnaround target, and escalation speed.
Step 4: Build the minimum control layer
Create lightweight rules: what is auto-routed, what is human-reviewed, what is blocked, and what is escalated.
Step 5: Introduce Comments Manager at the bottleneck
Implement the feature only in the scoped segment. Track before/after metrics.
Step 6: Add exception handling depth
Design edge-case routes early. A system without exception depth works only on easy days.
Step 7: Run weekly audits
Use a fixed template: metric movement, major failures, near misses, corrective actions, owner deadlines.
Step 8: Expand carefully
Scale to the next segment only after two stable audit cycles.
Mini-example: a mid-size agency used this sequence on campaign response operations. They improved cycle time first, then discovered rising rework due to tone drift. After adding a QA gate and tighter escalation thresholds, quality recovered while speed held.
Failure modes, edge cases, trade-offs, and decision matrix
Common failure modes
Ambiguous escalation: team members know something is wrong but not who decides.
Metric theater: dashboards improve while business outcomes do not.
Coverage obsession: pressure to automate everything too early.
Input quality decay: weak briefs produce weak outputs at scale.
Rollback paralysis: no clear method to pause harmful workflows.
Edge cases that deserve explicit handling
Viral spikes that multiply low-intent interactions.
Sensitive claims requiring policy checks.
Multi-language threads with tone drift risk.
Creator collaborations where approval rights are shared.
Weekend or off-hour incidents with reduced staffing.
Trade-offs to manage deliberately
Speed vs precision: faster routing may reduce contextual nuance.
Consistency vs adaptability: strict templates improve reliability but can flatten brand voice.
Centralization vs autonomy: central controls reduce risk, but local teams may respond slower to niche audience cues.
Short-term efficiency vs long-term resilience: aggressive automation can save hours now but increase correction debt later.
Decision matrix (practical)
SituationRecommended actionWhyHigh routine volume, low sensitivityIncrease standardized handlingGains speed with manageable riskModerate volume, mixed sensitivityHybrid model with escalation gatesBalances throughput and judgmentLow volume, high sensitivityKeep human-led workflowProtects nuance and risk controlRising exceptions week-over-weekPause expansion, audit root causesPrevents quality collapseTeam overload despite speed gainsReduce scope and add workload balancingSustainability before scale
Use this matrix during weekly reviews. It prevents reactive changes driven by one noisy day.
FAQ
1) What should we automate last?
Anything with high reputational or compliance sensitivity should be automated last. Keep human review as the default in these classes until your exception history shows stable control.
2) How many metrics are enough?
Five is usually enough at launch: throughput, cycle time, rework, escalation volume, and conversion quality. Add more only when a concrete decision requires it.
3) How do we prevent brand voice drift?
Use a short voice rubric, example library, and weekly calibration review. Drift is usually a governance issue, not a writing issue.
4) When should we rollback?
Rollback when two consecutive audit cycles miss quality thresholds, or when one severe failure exposes risk beyond your current controls.
5) How do we scale without burning the team out?
Protect cognitive load: reduce context switching, rotate exception ownership, and cap concurrent experiments. Sustainable pace is a performance strategy, not a wellness slogan.
6) What is the smallest viable governance layer?
One workflow owner, one escalation owner, one approval checklist, and one weekly audit ritual. That is enough to start.
Key Takeaways
Build scale on decision quality, not activity volume.
Use the SIGNAL Loop to make operations explicit, measurable, and improvable.
Deploy Comments Manager where bottlenecks are clear and outcomes are measurable.
Design failure handling before broad rollout; exceptions define system maturity.
Expand only after stable audits prove both quality and team sustainability.
Advanced implementation layer: decision depth for contest growth
Scenario planning across maturity stages
Early-stage teams often overestimate their ability to run complex contest workflows setups. A more reliable approach is stage-gated maturity. In stage one, define one narrow objective and one service-level promise. In stage two, add a second channel only after error and escalation rates remain stable for at least two review cycles. In stage three, improve sophistication by introducing segmented rules, but only if your audit process can detect quality decay fast enough.
The reason this matters is organizational memory. If your process depends on one experienced operator “knowing what to do,” the system is fragile. Maturity requires documented rules that a new hire can follow with minimal ambiguity. For leaders, that means measuring transferability: can a teammate step in without causing output volatility? If not, your model is not scalable yet.
Mini-example: a team expanded from one campaign queue to three channels in a single sprint. Throughput increased temporarily, but exception ownership became unclear and closure time doubled. They recovered only after returning to staged rollout and defining explicit queue ownership.
Failure containment and rollback architecture
Most teams think about optimization first and rollback second. That is backwards. High-reliability teams design failure containment before broader rollout. Containment includes kill-switch criteria, fallback playbooks, and communication templates for internal and external stakeholders. If a workflow starts generating errors, the team should know exactly who can stop it, what gets paused, and how pending items are triaged.
A practical rollback architecture has three tiers. Tier 1 is local rollback (single workflow pause). Tier 2 is partial rollback (channel-level scope reduction). Tier 3 is global rollback (all automated or semi-automated actions paused while human triage takes over). Each tier should have pre-defined triggers and recovery checks.
Use risk classes to reduce debate during incidents. For example, quality drift with low impact can remain in Tier 1. Reputational risk with fast spread potential should trigger Tier 2 immediately. Policy or legal-adjacent uncertainty can justify Tier 3 until review is complete. This structure reduces emotional decision-making when time pressure is high.
Economics and trade-off calibration
Operational design must include economics, not just mechanics. Ask three questions: (1) Which tasks create the most avoidable labor hours? (2) Which failures create the most expensive rework? (3) Which improvements protect conversion quality under load? The best investment is rarely the flashiest capability; it is usually the one that reduces recurring friction in a high-frequency step.
Trade-off calibration should be reviewed monthly. If speed gains come with higher correction costs, net performance may decline despite “better” dashboards. If consistency improves but engagement quality drops, your system may be too rigid. Leaders should evaluate contribution margin of process changes, not just activity metrics.
For many teams, the hidden cost is management overhead. Every additional rule, exception path, or template requires maintenance. If your governance surface grows faster than your team’s review capacity, complexity debt accumulates. The cure is periodic simplification: retire low-impact rules, merge overlapping steps, and reduce unnecessary branch logic.
Edge-case library and decision hygiene
Edge cases are where brand trust is won or lost. Build a lightweight edge-case library with examples, decisions taken, rationale, and outcome notes. Over time, this becomes the fastest way to train new operators and align cross-functional partners. It also prevents repetitive debates because teams can reference prior logic instead of restarting from zero.
Decision hygiene matters as much as decision speed. Good hygiene means stating assumptions, identifying risk class, naming owner, and setting review date. Without those elements, teams create “sticky” decisions that persist long after conditions change.
A useful ritual is a 30-minute weekly decision review:
Which assumptions were wrong?
Which edge cases repeated?
Which rules caused false escalations?
Which exceptions should become standard paths?
Which standards should be relaxed to restore agility?
This ritual keeps the system adaptive without becoming chaotic. It also improves psychological safety, because teams learn to discuss failures as design signals rather than personal mistakes.
Practical scorecard for the next 90 days
Use a balanced scorecard to validate that the model is improving both performance and sustainability.
Performance metrics
Median cycle time trend
Conversion-quality trend
Rework rate trend
Risk metrics
Severe incident count
Escalation miss rate
Policy-alignment exceptions
People metrics
Overtime frequency
Context-switching load
Operator confidence score
System metrics
Rollback readiness checks passed
Audit completion rate
Rule-set complexity index
Set directional targets, not vanity goals. For example: reduce rework by 20% while keeping conversion quality stable; decrease overtime incidents without increasing unresolved queue age. If the scorecard improves in one domain but worsens sharply in another, pause scaling and re-balance the design.
Where Comments Manager creates compounding value
Comments Manager delivers compounding value when it is embedded into a stable review loop rather than used as a one-time acceleration tool. The first gains often come from reducing repetitive handling. The second-order gains come from better visibility and cleaner handoffs. The third-order gains come from organizational learning: teams identify recurring patterns faster, adjust rules earlier, and avoid repeating the same mistakes.
Compounding requires discipline. Keep ownership explicit, keep audits frequent, and keep exception handling visible. If any of those layers is missing, gains flatten quickly. With those layers in place, teams can increase output while protecting quality, operator capacity, and brand integrity.



